在AI界的一次意外曝光中,一篇看似不起眼的博客文章竟成为了打开OpenAI大门的钥匙。近日,AI云服务商Hyperbolic的联合技术官Yuchen Jin在社交媒体上透露,研究员Keller Jordan仅凭一篇关于新型神经网络优化器Muon的博客,便成功加入了OpenAI,并疑似参与到了GPT-5的研发中。
Jin的这一爆料迅速引起了业界的广泛关注。据悉,Keller Jordan的这篇博客发布于2024年12月,题为《Muon:神经网络隐藏层的优化器》。文章详细介绍了Muon的设计原理及其在实际应用中的表现,特别是在提高训练速度方面的显著成果。
Keller Jordan在博客中提到,Muon是一个专门针对神经网络隐藏层二维参数的优化器。它通过结合SGD-momentum生成的更新,并应用牛顿-舒尔茨迭代法作为后处理步骤,来优化这些参数。这种方法使得更新矩阵近似正交化,从而提高了训练效率。
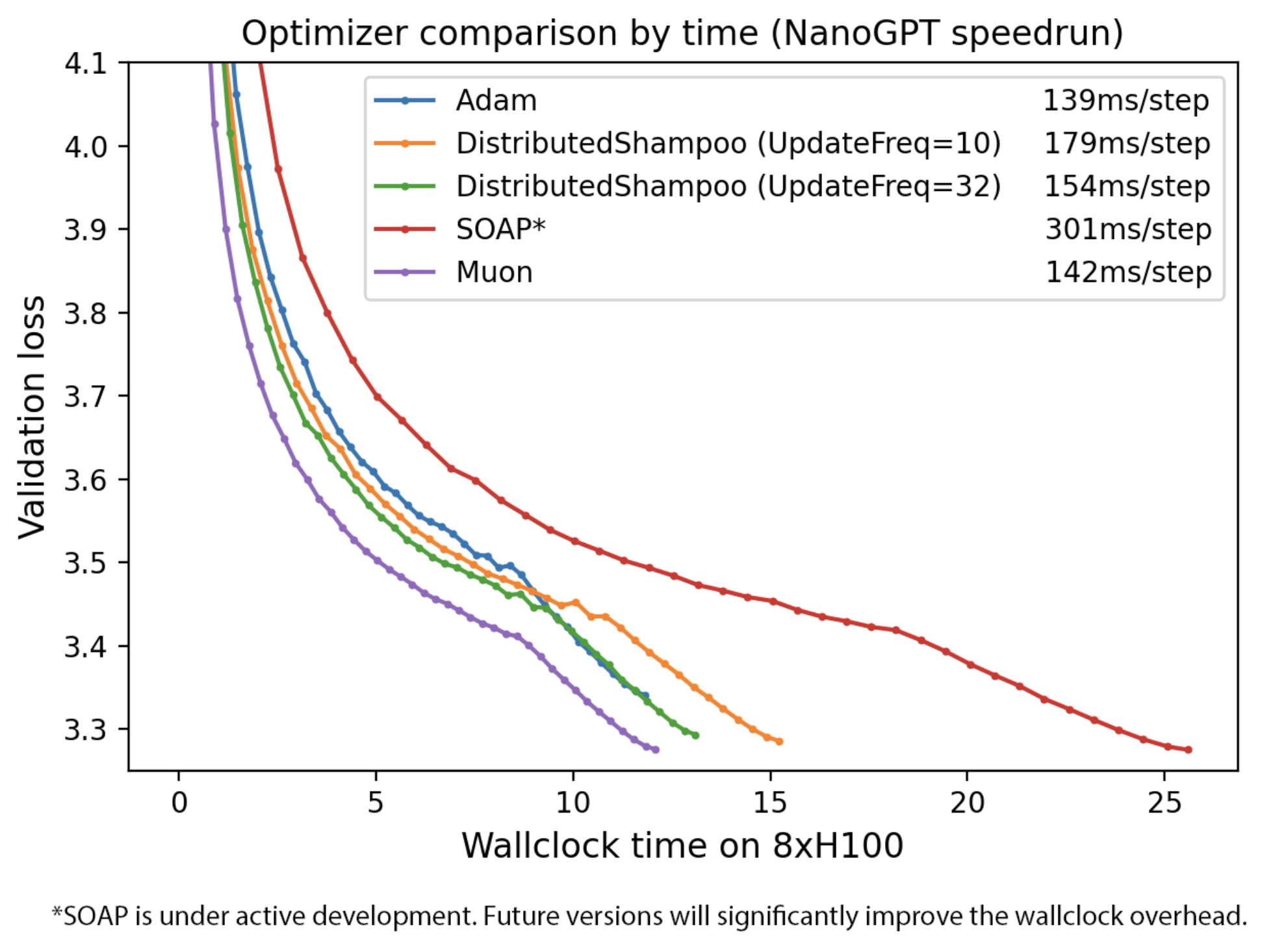
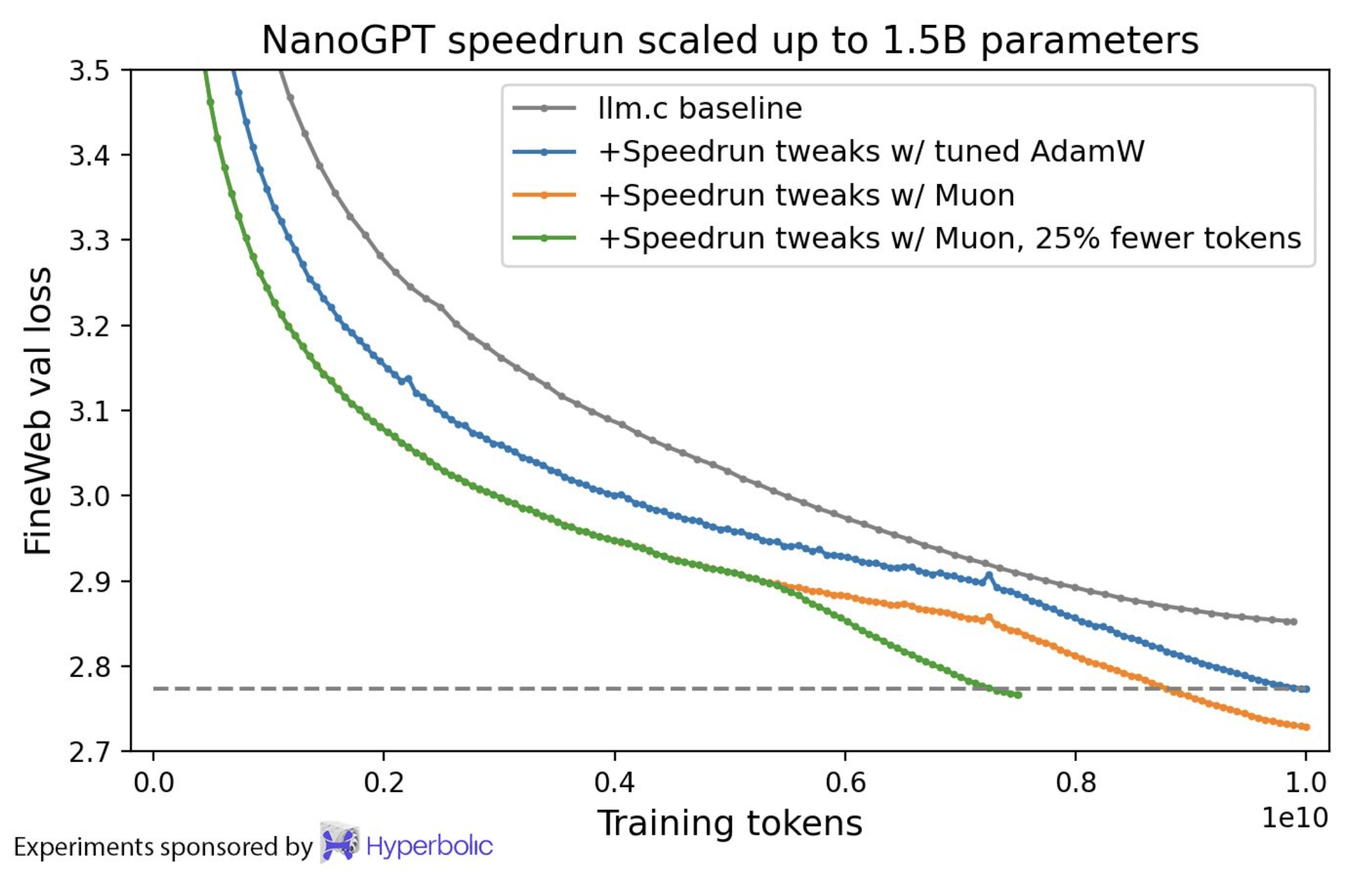
实验结果显示,Muon在多个任务上都取得了显著的速度提升。例如,在CIFAR-10数据集上,它将训练速度记录从3.3秒提高到了2.6秒,准确率保持在94%。在NanoGPT快速运行竞赛任务FineWeb上,Muon也将训练速度记录提高了1.35倍。在扩展到更大规模参数时,Muon也继续显示出训练速度的提升。
Keller Jordan在文章中还批判了当前神经网络优化研究中的一些不良现象,特别是糟糕的基线和过度宣传的新方法。他强调,许多声称能够击败AdamW的优化器在实际应用中并未能达到预期效果,这主要是因为这些研究在比较时往往没有充分调整AdamW基线。
Keller Jordan加入OpenAI的时间恰好是在他发布这篇博客之后。这一巧合不禁让人猜测,Muon优化器很可能正是他加入OpenAI的敲门砖。而鉴于OpenAI在GPT-5研发上的投入和期望,Muon很有可能成为这一划时代大模型中的重要技术之一。
然而,尽管Muon已经取得了显著的成果,但仍有许多问题有待解决。例如,Muon是否可以扩展到更大规模的训练?是否能在大型GPU集群中正确分布其使用的牛顿-舒尔茨迭代?以及Muon是否仅适用于预训练,而不适用于微调或强化学习工作负载?这些问题或许在GPT-5的研究中已经得到了答案,但业界仍需持续关注Muon的发展和应用。
总的来说,Keller Jordan的这篇博客不仅为神经网络优化研究带来了新的思路和方法,也为他个人的职业生涯开启了新的篇章。而Muon优化器作为这一研究的成果,无疑将在未来的AI发展中发挥重要作用。