银河通用公司近期震撼发布了一款名为TrackVLA的全球首创产品级端到端具身FSD大模型。这款模型集成了纯视觉环境感知、语言指令驱动、自主推理及零样本泛化能力,标志着人工智能领域的一大突破。
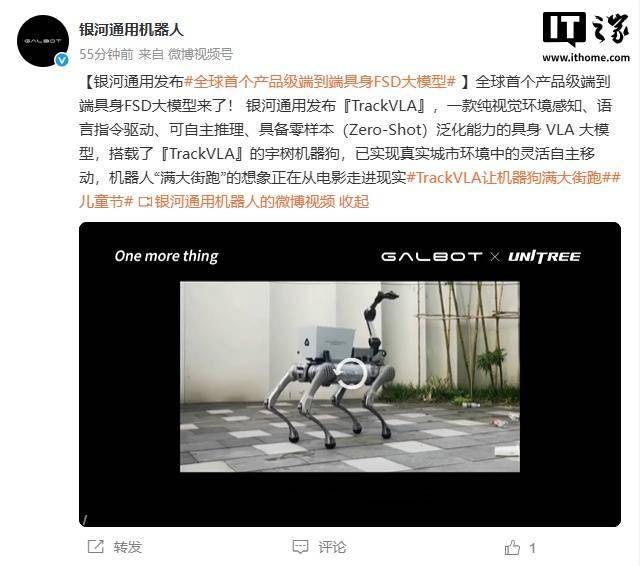
TrackVLA是一款专为机器人导航设计的产品级大模型,它结合了“视觉-语言-动作”(VLA)训练框架,通过仿真合成动作数据进行训练。这一创新使机器人能够形成“听 → 看 → 懂 → 走”的闭环运动能力,无需预先建图或依赖遥控操作,仅需语言指令即可驱动。
这款大模型的八大核心能力令人瞩目:
首先,TrackVLA具备出色的自然语言理解和目标识别能力。用户只需简单发出指令,如“跟着妈妈”,机器人便能迅速锁定目标,并根据用户的新指令,如“换成跟孩子”,立即切换跟随对象。这种能力不仅限于人类,甚至还能跟踪宠物。
其次,在人流密集的场景中,TrackVLA展现出卓越的空间理解和视觉记忆机制。它能准确识别并持续跟随目标,即便在多变环境和多个相似穿着的人中,也能避免“认错人”。
第三,当目标走出视野范围时,TrackVLA不会停滞不前,而是利用实时空间智能和大模型推理能力,分析目标运动轨迹,重新规划路径找回目标。
第四,TrackVLA不依赖建图,仅凭纯视觉输入理解环境。这意味着它可以在未经训练的陌生环境中,如商场、电梯、游乐区等,实现长时稳定自主跟随。

第五,在复杂场景中,如儿童游乐区和狭窄通道,TrackVLA能实时识别障碍物,分析可通行区域,并根据自身构型自主推理出合理路线,灵活避障。
第六,TrackVLA展现出极强的环境适应性,无论室外阳光还是室内昏暗,从电梯镜面反射到超市货架夹缝,都无需专门调参或切换模式。
第七,用户可通过App实时查看机器人视角,掌握家人动态,系统还能主动提醒风险行为,如小朋友奔跑或老人跌倒,提供“移动守护”。
最后,TrackVLA的技能涌现能力令人惊叹。它不仅能稳定跟随人类,还能泛化至任意移动目标。例如,在视频中,机器狗成功跟随一只偶遇的动物狗狗,尽管目标形态、运动方式和遮挡情况都非常不确定,但TrackVLA仍表现出稳定的跟随能力。
目前,TrackVLA已搭载于宇树机器狗,化身“二宝保镖”,实现儿童看护,并在未训练过的真实场景中完成了严格的长程验证。在超市、电梯、服装店等环境中,它成功穿梭于人流和货架之间,准确跟随母子,根据语音指令切换目标,并在儿童玩耍时发出提醒,展现出卓越的性能。