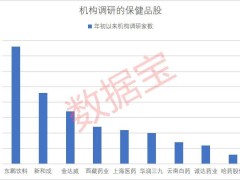
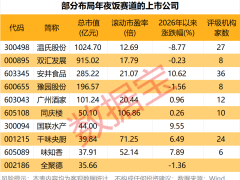
在近日于昆山举办的光合组织人工智能创新大会上,中科曙光正式推出全球首套国产万卡级AI集群系统——scaleX万卡超集群,并以真机形式完成首次公开展示。该系统凭借多项突破性技术指标,成为国产智算基础设施领域的里程碑式成果,标志着我国在高端AI算力领域实现从跟跑到局部领跑的跨越。
据中科曙光高级副总裁李斌介绍,该系统专为万亿参数大模型训练、科学智能计算等前沿场景设计,通过架构创新与系统级优化,在算力密度、网络性能、能效比等核心指标上达到国际领先水平。系统由16个自主研发的scaleX640超节点构成,通过scaleFabric高速互连网络实现10240块AI加速卡协同工作,总算力规模突破5EFlops,相当于500万台高性能服务器的计算能力。
在硬件架构层面,scaleX640超节点采用全球首创的单机柜640卡设计,通过浸没式相变液冷技术与高密度刀片服务器集成,将单机柜算力密度提升至传统方案的20倍,同时将电源使用效率(PUE)优化至1.04的行业最低水平。这种设计不仅显著降低数据中心能耗,更通过模块化架构支持灵活扩展,可满足从千卡到十万卡级集群的弹性部署需求。
网络通信方面,曙光自主研发的scaleFabric系统搭载国内首款400G原生RDMA网卡与交换芯片,实现400Gb/s超宽带宽与亚微秒级通信延迟。相比传统InfiniBand网络,该方案将集群规模扩展能力提升2.33倍,网络建设成本降低30%,同时通过智能流量调度算法确保万卡级并发训练时的数据传输零丢包。
针对大模型训练特有的存储挑战,系统创新采用"存算传"三级协同优化技术。通过芯片级数据预取、系统级缓存加速和应用级流式传输的深度融合,使万卡集群并发读写带宽提升3倍,AI推理响应速度缩短40%,加速卡资源利用率提高55%。这项突破有效解决了传统架构中存储瓶颈导致的算力闲置问题。
在运维管理层面,系统构建了数字孪生与智能调度双引擎。数字孪生平台可实时映射物理集群运行状态,实现故障预测准确率达92%的智能运维;智能调度引擎则支持每秒万级作业分发,可同时管理十万级用户请求,确保集群长期可用性达到99.99%的电信级标准。
作为"AI计算开放架构"的旗舰产品,scaleX万卡超集群已完成与400余个主流大模型的适配优化,支持多品牌加速卡混合部署。在实际应用中,该系统已成功应用于金融风控模型训练、地质勘探数据处理、气候模拟等关键领域,其中某金融机构的万亿参数模型训练效率较传统方案提升6倍。
该系统的推出得益于中科曙光联合20余家产业链伙伴构建的开放生态。通过共享液冷技术、RDMA协议栈等12项关键共性技术,生态伙伴可基于统一架构快速开发定制化解决方案,将智算集群研发周期从18个月压缩至6个月。这种"技术共研、生态共建"的模式,正在推动我国AI基础设施从单机性能竞争转向系统能力比拼的新阶段。