站在门口看一眼,AI 就能脑补出房间里面长什么样:

是不是有线上 VR 看房那味儿了?不只是室内效果,来个远景长镜头航拍也是 so easy:

而且渲染出的图像通通都是高保真效果,仿佛是用真相机拍出来的一样。最近一段时间,用 2D 图片合成 3D 场景的研究火了一波又一波。但是过去的许多研究,合成场景往往都局限在一个范围比较小的空间里。比如此前大火的 NeRF,效果就是围绕画面主体展开。

这一次的新进展,则是将视角进一步延伸,更侧重让 AI 预测出远距离的画面。
比如给出一个房间门口,它就能合成穿过门、走过走廊后的场景了。

目前,该研究的相关论文已被 CVPR2022 接收。
输入单张画面和相机轨迹
让 AI 根据一个画面,就推测出后面的内容,这个感觉是不是和让 AI 写文章有点类似?实际上,研究人员这次用到的正是 NLP 领域常用的 Transformer。他们利用自回归 Transformer 的方法,通过输入单个场景图像和摄像机运动轨迹,让生成的每帧画面与运动轨迹位置一一对应,从而合成出一个远距离的长镜头效果。
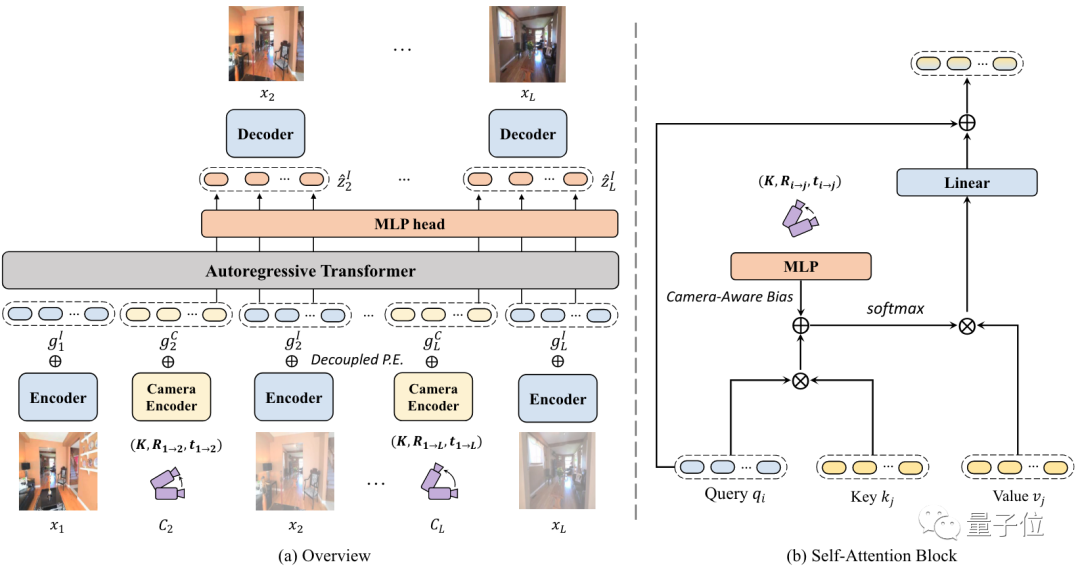
整个过程可以分为两个阶段。
第一阶段先预训练了一个 VQ-GAN,可以把输入图像映射到 token 上。VQ-GAN 是一个基于 Transformer 的图像生成模型,其最大特点就是生成的图像非常高清。在这部分,编码器会将图像编码为离散表示,解码器将表示映射为高保真输出。
第二阶段,在将图像处理成 token 后,研究人员用了类似 GPT 的架构来做自回归。具体训练过程中,要将输入图像和起始相机轨迹位置编码为特定模态的 token,同时添加一个解耦的位置输入 P.E.。然后,token 被喂给自回归 Transformer 来预测图像。模型从输入的单个图像开始推理,并通过预测前后帧来不断增加输入。
研究人员发现,并非每个轨迹时刻生成的帧都同样重要。因此,他们还利用了一个局部性约束来引导模型更专注于关键帧的输出。这个局部性约束是通过摄像机轨迹来引入的。基于两帧画面所对应的摄像机轨迹位置,研究人员可以定位重叠帧,并能确定下一帧在哪。
为了结合以上内容,他们利用 MLP 计算了一个“相机感知偏差”。这种方法会使得在优化时更加容易,而且对保证生成画面的一致性上,起到了至关重要的作用。
实验结果
本项研究在 RealEstate10K、Matterport3D 数据集上进行实验。结果显示,相较于不规定相机轨迹的模型,该方法生成图像的质量更好。

与离散相机轨迹的方法相比,该方法的效果也明显更好。

作者还对模型的注意力情况进行了可视化分析。结果显示,运动轨迹位置附近贡献的注意力更多。

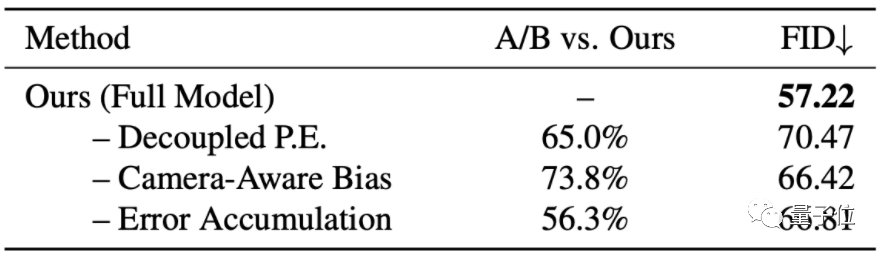
在消融实验上,结果显示该方法在 Matterport3D 数据集上,相机感知偏差和解耦位置的嵌入,都对提高图像质量和帧与帧之间的一致性有所帮助。
两位作者均是华人
Xuanchi Ren 为香港科技大学本科生。

他曾在微软亚研院实习过,2021 年暑期与 Xiaolong Wang 教授有过合作。
Xiaolong Wang 是加州大学圣地亚哥分校助理教授。

他博士毕业于卡内基梅隆大学机器人专业。研究兴趣有计算机视觉、机器学习和机器人等。特别自我监督学习、视频理解、常识推理、强化学习和机器人技术等领域。
论文地址:
https://xrenaa.github.io/look-outside-room/